STEP THREE – Assessing and Entering your Org, Reports, Reporting Units and Summaries
Mapping data into the WaDE database
Before starting the data mapping phase it is highly recommended that you download and review the defined list of data elements for the data that are intended to be shared by the WaDE project. This will help immensely with the step-by-step instructions below. Mapping of your data over to the WaDE database includes five basic steps.
- Setting up your organization’s contact data.
- Assessing what Reports, Reporting Units, and what ‘Summary’ types of water information you may have (data for availability, allocations, use, water supply, and regulatory constraints summarized by a geospatial unit).
- Populating the associated ‘Methods’ and ‘Lookup’ tables for the summaries.
- Assessing what ‘Detailed’ types of water information you may have (data for water rights, locations for diversions, uses and return flows), and entering these into the ‘Detailed’ data tables.
- Populating the associated ‘Methods’ and ‘Lookup’ tables for the more detailed data.
Setting up your Contact Information
Open the ORGANIZATION table in edit mode and use the sample data in the table as a guide for entering your organization’s contact information into the table. Your ORGANIZATION_ID must be a unique and short combination of letters and/or numbers. For example, a good ORGANIZATION_ID for Colorado Water Conservation Board would be ‘COWCB.’ ORGANIZATION_NAME should be the full name of your organization. Fill out the remaining columns with the contact information for a staff member that is willing to be the go-to contact for WaDE-published information. The WADE_URL column will host the root address for the webservices up to the WADE folder. For example, if your web server root address is https://www.westernstateswater.org, and you want to host your WaDE node on https://www.westernstateswater.org/DEMO/WADE/v0.2/GetCatalog/GetCatalog.php?loctype… then you would put https://www.westernstateswater.org/DEMO into the WADE_URL column. Omit the trailing forward-slash.
Reports
Within the WaDE schema, reports are used as time encapsulations of the data. They are an annual ‘report’ for water data, but can be for a water year, a calendar year or even an irrigation year if that is what your organization uses to organize your information primarily. The report is used to organize both summary data and also detailed, site-specific data. Data within an annual report can also be broken down into monthly time increments if your organization can report data at that scale in associated tables. You can also have multiple reports for any given year. For example, if you have annual water use estimates using both Blaney-Criddle and Penmen-Monteith methods for the year 2014, you might name your first report ‘2014-PM,’ and your second report ‘2014-BC’. These will both show up in your organization’s catalog query return, and the user will also be able to access your methodology information to discover which method is best suited for their purposes.
After evaluating what data you’d like to include in your annual reports, open the REPORT table, enter your ORGANIZATION_ID, and the year for the report you will offer in the REPORT_ID column. Under REPORTING_DATE and REPORTING_YEAR enter the date that this information was/will be published (e.g. first of the year, or today’s date) and the year which the data describe, respectively. You can give your reports a specific descriptive name under REPORT_NAME and also add a hyperlink to an actual report or webpage that further explains the data shared in the report using REPORT_LINK. Finally, for YEAR_TYPE, enter “CY” for “Calendar Year,” “WY” for “Water Year,” or “IY” for irrigation year; whichever is most appropriate for your organization. Use the sample data as a guide.
Reporting Units
Each state has its own geospatial way of organizing or summarizing water information. Some use county boundaries, some use HUCS, some use HUCS combined with state boundaries, while others use a completely custom delineation (e.g. districts, divisions, WABs). Within the WaDE terminology, we call these “reporting units.” The WaDE portal allows you to select one of these geographic units for summarizing data. Determine which of the above is the best fit for the way that you summarize your data at this time. If you use a HUC, you will use the HUC number (at any level of digit) to access the summary for that HUC within WaDE. If you use counties, you will use a FIPS code for the county. If you use HUCs combined with states, you will use a custom reporting unit identification number that combines the HUC number and the state code (i.e., 16020204_UT). If your reporting unit is entirely customized, you may use the identification number that you use to access that shape within your database.
In the database your identification number is referred to by the REPORT_UNIT_ID. Open the REPORTING_UNIT table and, using the sample data as a guide, enter your ORGANIZATION_ID and REPORT_IDs as before, followed by the REPORT_UNIT_ID unique identifier. If you have many summaries and many reporting units, it may be easier to automate this process by importing exporting a .dbf from a GIS file, into a .csv file and importing this. Enter the name for the reporting unit in the REPORTING_UNIT_NAME column and the reporting unit type in the REPORTING_UNIT_TYPE. Enter your state’s identification number in STATE (use the number for your state in the LU_STATE table), as well as the FIPS Code or HUC number if applicable.
Summary Data Tables
Assess what type of summarized water data your organization oversees (data summarized by a specific geographic unit such as a watershed, county or other custom delineation). The WaDE schema can accommodate five different types of summaries: Water Availability Summaries, Water Allocation Summaries, Water Use Summaries, Derived Water Supply Summaries, and Regulatory Summaries. Each of these can be supplied within a “report” for any given water, calendar or irrigation year. Please see the table below for a more in-depth description of each type of summary.
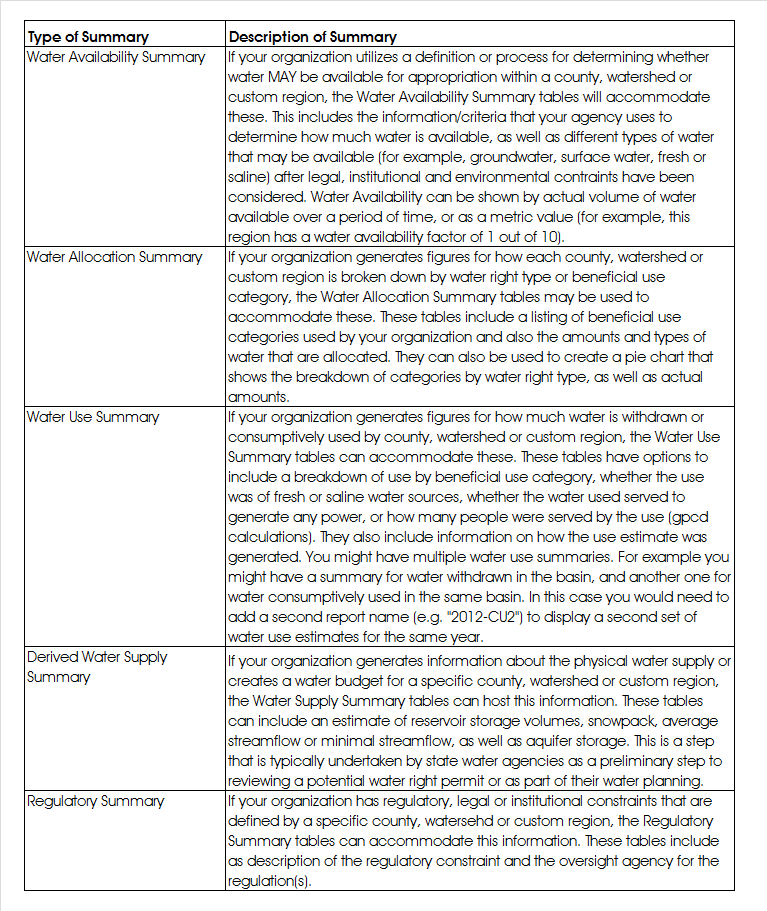
Other Summary Tables
Each main summary table uses a “SUMMARY_” prefix. Secondary tables have an “S_” prefix. Step through each summary table that is relevant for your data and, using the look-up tables and sample data as a guide, populate them with your data. The easiest way to do this would be to automate the process of exporting the relevant information out of your native databases directly into the WaDE database using the SQL Import/Export Wizard, customized View tables, or via .csv files that can then be imported (either to overwrite or append existing data). You’ll notice that each summary table uses the same ORGANIZATION_ID, REPORT_ID and REPORT_UNIT_ID. This is how WaDE selects for your data for return to the client via the web services code.
Look-up Tables and Methods Tables
Some data used by state water planning programs is redundant, so look-up tables (with the prefix “LU_”) are employed in some cases where the same types of data are accessed more than once. An example would be types of units. Summaries and allocations use different units, such as “acre-feet per year” or “cubic feet per second.” The LU_UNITS look-up table is set up to house this kind of data while using the LU_SEQ_NO as the unique key for each value in the table. The METHODS and METRICS tables are similar. The listing of tables below shows the sequence or hierarchy of the summary tables and their secondary, look-up and methodology tables. Please proceed through the tables, filling in data using this sequence below. Once you’ve figured out what types of data go where, you can automate the importation process from your native databases.
Geospatial Data
If you have geospatial data related to either your Summary or Detailed data, you may send the layers to Sara so that she can set them up as Web Feature Services (WFS) on ArcGIS online (AGOL), or stand them up from your own geo-server or using AGOL. Use the WFS address in the WADE.GEOSPATIAL_REF table for each GIS file you’d like to share. All of the DETAIL and SUMMARY tables have a column called “WFS_FEATURE_REF” that can be used to tie the individual estimate back to the correct shape in the identified WFS. This is a way to provide GIS data alongside each estimate, but not slow down the query results with larger XML/geoJSON/JSON data retrievals.
Follow the sequence in the table below to view both the hierarchy of main summary tables and the secondary, look-up and methods tables. Many of the tables have foreign key relationships to the look up and methods tables, so you will need to work on those beforehand or while you are working on any given summary. Use the sample data as a guide to filling in the tables.
